Principle Componenets Analysis
I have tried to learn machine learning a few times. However, I never find the chance to implement any machine learning algorithm in my research. Here, I want to revisit the subject by reading Goodfellow’s book. I like simple things, because they help me understand the basic concept and gain intuition to the abstract math. Principle componenets analysis is such a simple thing, which I shall take some notes here to try to understand.
The problem – data compression
We want to compress a collection of points \( {x^{(1)}, …, x^{(m)}} \) in \(\mathbb{R}^n\) into code points \( {c^{(1)}, …, c^{(m)}} \) in \(\mathbb{R}^l\), where \( n>l \). We want an encode \( f(\mathbf{x})=\mathbf{c}\) and a decoder \( g(\mathbf{c}) \approx \mathbf{x}\).
A simple choice of the decoder is a matrix \( \mathbf{D} \) in \( \mathbb{R}^{n\times l}\), \( g(\mathbf{c}) = \mathbf{D}\mathbf{c}\). The goal is to find the best encoder and decoder, so that the distance between original points \(\mathbf{x}\) and the reconstructed points \(\mathbf{r}\) is minimized. Formally, we want to solve the following optimization:
\[\mathbf{D} ^ * = \mathrm{arg\,min}_{\mathbf{D}} \sum_i || \mathbf{x}^{(i)} - \mathbf{r}^{(i)} ||_2 .\]where \( \mathbf{r} = g(f(\mathbf{x})) = \mathbf{D}f(\mathbf{x})\). To make the problem solvable, we need to figure out what is the encoder \(f(x)\). One way to do this is to make the distance between the reconstructed points closest to the original points, formally:
\[\mathbf{c}^* = \mathrm{arg\,min}_{\mathbf{c}} || \mathbf{x} - g(\mathbf{c}) ||_2 .\]This is equivalent to
\[\mathrm{arg\,min}_{\mathbf{c}} || \mathbf{x} - g(\mathbf{c}) ||_2^2\]we can expand the square:
\[\mathrm{arg\,min}_{\mathbf{c}} (\mathbf{x} - g(\mathbf{c}))^\top (\mathbf{x} - g(\mathbf{c}))\] \[\mathrm{arg\,min}_{\mathbf{c}} \mathbf{x}^\top\mathbf{x} - g(\mathbf{c})^\top \mathbf{x} - \mathbf{x}^\top g(\mathbf{c}) + g(\mathbf{c})^\top g(\mathbf{c})\]\(\mathbf{x}^\top\mathbf{x}\)is irrelevant since it does not contain \(\mathbf{c}\)we are optimizing. \(g(\mathbf{c})^\top \mathbf{x}\) and \(\mathbf{x}^\top g(\mathbf{c})\) are scalars, so they are equal. At this point, we can substitute the exact form of \(g(\mathbf{c})\), the objective function becomes
\[\mathrm{arg\,min}_{\mathbf{c}} - 2 (\mathbf{D}\mathbf{c})^\top \mathbf{x} + (\mathbf{D}\mathbf{c})^\top \mathbf{D}\mathbf{c}\] \[\mathrm{arg\,min}_{\mathbf{c}} - 2 \mathbf{c}^\top \mathbf{D}^\top \mathbf{x} + \mathbf{c}^\top \mathbf{D}^\top \mathbf{D}\mathbf{c}\] \[\nabla_{\mathbf{c}} (- 2 \mathbf{c}^\top \mathbf{D}^\top \mathbf{x} + \mathbf{c}^\top \mathbf{D}^\top \mathbf{D}\mathbf{c}) \\ = - 2 \mathbf{D}^\top \mathbf{x} + 2 \mathbf{D}^\top \mathbf{D}\mathbf{c}\]The 0-gradient point corresponds to a local minimum, which is the \(\mathbf{c}^*\) we are looking for.
\[\mathbf{x} = \mathbf{D} \mathbf{c}^*,\, \mathbf{c}^* = \mathbf{D}^\top\mathbf{x}\]The best encoder \(f(\mathbf{x})\) is found to be \(\mathbf{D}^\top\mathbf{x}\).
Next, we solve the optimization for \( \mathbf{D}^* \) to minimize the distance between original data \(\mathbf{x}\) and reconstruction \(\mathbf{r} = \mathbf{D}\mathbf{D}^\top\mathbf{x}\).
\[\mathbf{D} ^ * = \mathrm{arg\,min}_{\mathbf{D}} \sum_i || \mathbf{x}^{(i)} - \mathbf{D}\mathbf{D}^\top\mathbf{x}^{(i)} ||_2\]To simplify the derivation, we can look at a special case where \(l=1\), i.e. \(\mathbf{D}\) is \(\mathbb{R}^1\). We denote \(\mathbf{D}\) in this special case \(\mathbf{d}\), and rewrite the objective function
\[\mathbf{D} ^ * = \mathrm{arg\,min}_{\mathbf{d}} \sum_i || \mathbf{x}^{(i)} - \mathbf{d}\mathbf{d}^\top\mathbf{x}^{(i)} ||_2\]The summation can be written in a more compact form if we let \( \mathbf{X}_{i, :} = \mathbf{x}^{(i)\top} \), or
\[\mathbf{X} = \begin{bmatrix} \mathbf{x}^{(1)\top} \\ \vdots \\ \mathbf{x}^{(m)\top} \end{bmatrix}\]we can write the objective function as
\[\mathbf{D} ^ * = \mathrm{arg\,min}_{\mathbf{d}} \sum_i || \mathbf{x}^{(i)\top} - \mathbf{x}^{(i)\top} \mathbf{d}\mathbf{d}^\top||_2\]stack all the \( \mathbf{x}^{(i)\top} \)
\[\mathbf{D} ^ * = \mathrm{arg\,min}_{\mathbf{d}} || \mathbf{X} - \mathbf{X} \mathbf{d}\mathbf{d}^\top||_F\]Here, the subscript \(_F\) denotes Frobenius norm, which measures the size of a matrix. This norm can be written in trace form:
\[\begin{align} \mathbf{D} ^ * &= \mathrm{arg\,min}_{\mathbf{d}} \text{Tr}\left( \left( {\mathbf{X} - \mathbf{X} \mathbf{d}\mathbf{d}^\top}\right)^\top \left( {\mathbf{X} - \mathbf{X} \mathbf{d}\mathbf{d}^\top}\right) \right) \\ &= \mathrm{arg\,min}_{\mathbf{d}} \text{Tr}\left( \mathbf{X}^\top \mathbf{X} - \mathbf{d}\mathbf{d}^\top\mathbf{X}^\top\mathbf{X} - \mathbf{X}^\top\mathbf{X}\mathbf{d}\mathbf{d}^\top + \mathbf{d}\mathbf{d}^\top\mathbf{X}^\top \mathbf{X}\mathbf{d}\mathbf{d}^\top\right) \\ &= \mathrm{arg\,min}_{\mathbf{d}} \text{Tr}\left( \mathbf{X}^\top \mathbf{X} \right) - \text{Tr}\left(\mathbf{d}\mathbf{d}^\top\mathbf{X}^\top\mathbf{X} \right) - \text{Tr}\left( \mathbf{X}^\top\mathbf{X}\mathbf{d}\mathbf{d}^\top \right) + \text{Tr}\left( \mathbf{d}\mathbf{d}^\top\mathbf{X}^\top \mathbf{X}\mathbf{d}\mathbf{d}^\top \right) \\ &= \mathrm{arg\,min}_{\mathbf{d}} - \text{Tr}\left(\mathbf{d}\mathbf{d}^\top\mathbf{X}^\top\mathbf{X} \right) \\ &= \mathrm{arg\,max}_{\mathbf{d}} \text{Tr}\left(\mathbf{d}\mathbf{d}^\top\mathbf{X}^\top\mathbf{X} \right) \;\; \text{subject to} \; \mathbf{d}^\top\mathbf{d} = 1 \end{align}\]\( \mathbf{X}^\top \mathbf{X} \) can be eigendecomposed into \( \mathbf{V}\mathbf{\Lambda}\mathbf{V}^\top \), where \( \mathbf{V} \) is the eigenvector matrix \( [ \mathbf{v}^{(1)} \dots \mathbf{v}^{(n)} ] \) and \( \mathbf{\Lambda} \) is the diagonal matrix of eigenvalues \( \text{diag}(\lambda_i) \). Substitute the eigendecomposition into the objective function, we get
\[\mathrm{arg\,max}_{\mathbf{d}} \text{Tr}\left(\mathbf{d}\mathbf{d}^\top\mathbf{V}\mathbf{\Lambda}\mathbf{V}^\top \right) \, \text{subject to} \; \mathbf{d}^\top\mathbf{d} = 1 \\ = \mathrm{arg\,max}_{\mathbf{d}} \text{Tr}\left(\mathbf{d}^\top\mathbf{V}\mathbf{\Lambda}(\mathbf{d}^\top\mathbf{V})^\top \right) \, \text{subject to} \; \mathbf{d}^\top\mathbf{d} = 1\]Here \(\mathbf{d}^\top\mathbf{V}\) is a row vector. The result inside the trace is a scalar, and can be written as a summation of squares
\[\sum_i \lambda_i (\mathbf{d}^\top \mathbf{v}^{(i)})^2 = \sum_i \lambda_i \mathbf{v}^{(i)\top }\mathbf{d}\mathbf{d}^\top \mathbf{v}^{(i)}\]If we ignore the eigenvalue coefficient, the summation \( \sum_i (\mathbf{d}^\top \mathbf{v}^{(i)})^2 \) is the sum of \( \mathbf{d} \) components in \( \mathbf{V} \) space, so it is 1. To maximize the objective function, the best strategy is to let the largest eigenvalue have the biggest weight, which leads to
\[\mathbf{d} ^ * = \mathbf{v}^{(i)}, \, i = \mathrm{arg\,max}_j \lambda_j\]that is, the best encoder and decoder set is the eigenvector that corresponds to the largest eigenvalue. This makes sense. The eigendecomposition maps the original data onto the eigenvector space. The largest eigenvalue denotes the longest component of the data set in this space.
More principle components can be shown to be other large eigenvectors by proof of induction. The key steps are:
- when \(l = k\), assume
- when \(l = k + 1\)
\(\mathbf{D’}=[\mathbf{D}, \mathbf{d}]\). Since \(\mathbf{D’}\) is orthogonal, we cannot have the same vectors. The best choice of \(\mathbf{d}\) is the eigenvector that corresponds to the largest eigenvalue, which is not already in \(\mathbf{D}\). Therefore,
\[\mathbf{d} = \mathbf{v}^{(k+1)}\]It is also desired to have some examples of image compression. Let’s do a simple one.
import numpy as np
np.random.seed(0)
X = np.random.rand(100, 100) # random 2d array
XX = np.matmul(X.T, X) # X.T X
w, v = np.linalg.eig(XX) # eigendecomp
Then compute compression and reconstruction.
import matplotlib.pyplot as plt
for number_principle_components in [2, 50, 100]:
D = v[:, :number_principle_components]
C = D.T @ X
R = D @ C
fig, ax = plt.subplots(1, 2, figsize=(6, 3), dpi=100)
ax[0].imshow(X)
ax[1].imshow(R)
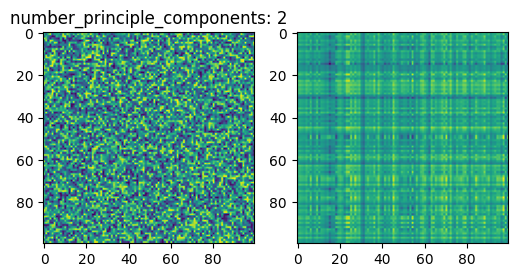
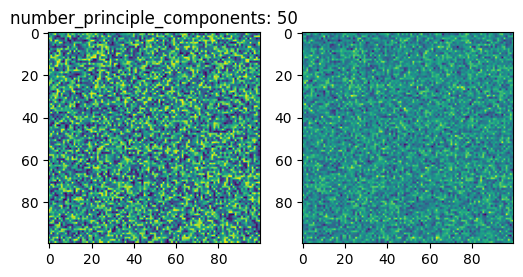
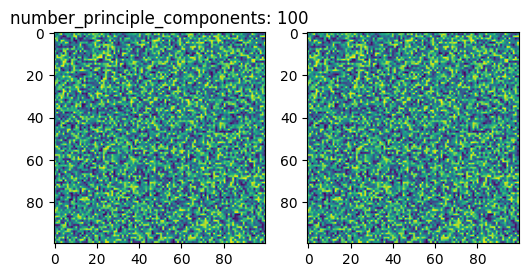

This is indeed a very simple compression algorithm, which does not recover good image quality.